ADO.NET data access¶
What is ADO.NET?¶
In data-driven applications, it is important for the data access layer to provide simple and convenient access to the database, making it easier to create complex queries. And all this should be as independent of the database engine itself as possible.
The ADO.NET (ActiveX Data Object) developed by Microsoft is a data access class library designed to meet these needs. As part of .NET, it provides a rich toolset for building data-driven applications, providing easy access to relational databases, regardless of the specific type of database.
ADO.NET is a powerful tool because it enables unified, database engine-independent access. The library contains interfaces and abstract classes that have many implementations (e.g., for Microsoft SQL Server or OleDB). And there are also third-party implementations compatible with ADO.NET for the databases that there is no built-in support.
The Entity Framework is also based on ADO.NET in the background.
The place of ADO.NET in a data-driven application architecture is as follows:
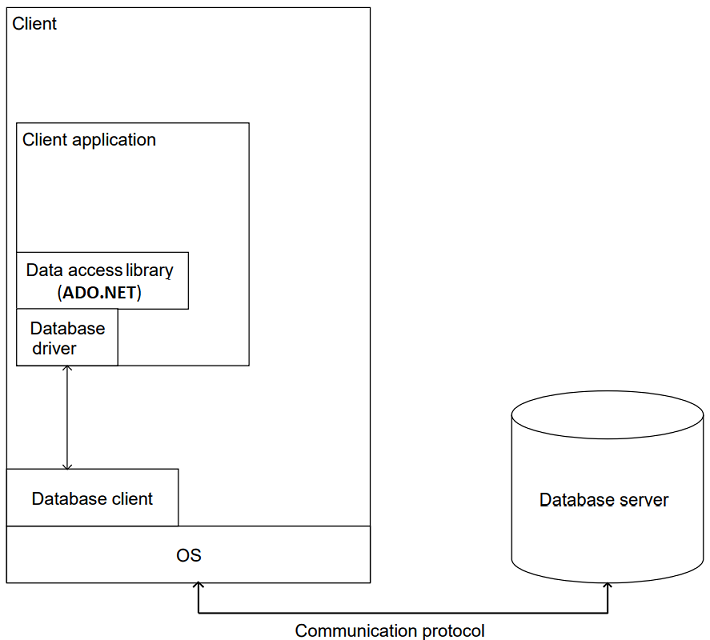
ADO.NET provides services in the data access layer and handles communication with the database engine in the background using drivers installed on the system and operating system services (such as a network connection).
The typical building blocks of data access libraries are:
- Connection - the database specific connection to the server
- Command - injection-safe command sent to the server
- ResultSet - result set returned by the server
- Exception - errors thrown by the library
These will be discussed in depth below.
Connection¶
The ADO.NET library provides the IDbConnection interface to represent database connections. It contains the functions needed to manage the connection to the database, such as Open(), Close(), or BeginTransaction(). This interface is implemented by database engine-specific connection classes, such as the SqlConnection class, which implements the connection to Microsoft SQL Server.
We need to know that setting up a new connection to a database is relatively expensive (opening a new network connection, negotiating protocols with the server, authentication, etc.). Therefore, we use connection pooling, where, after using and closing a connection, we do not discard it but put it back in a pool to reuse it later.
The availability of connection pool depends on the implementation; it supported by the MS SQL Server and OleDB implementations. Connection pools are created for every connection string (so not per database). This is important if the application does not use a single static connection string (but connects on behalf of the user, for example).
We also have to understand the problem of connection leak, which means that a connection is left open after use (we do not call Close()), so it is not returned to the pool, which prohibits future reuse. If we do leak connections this way, the pool will soon run out of connections, and the application will stop working due to not being able to talk to the database. This problem must be avoided by closing or disposing of connections safely (see sample code later).
We need the aforementioned connection string to connect to the database. It is a text variable that describes the parameters used to connect to the database, such as a username, password, or server address. Connection strings have database server-specific syntax and may also be a point of attacks.
The connection string can be stored as text in the configuration file, or the application code can build it. Below is a sample code creating a connection and using a ConnectionStringBuilder:
var builder = new SqlConnectionStringBuilder();
builder.UserID = "User";
builder.Password = "Pw";
builder.DataSource = "database.server.hu";
builder.InitialCatalog = "datadriven";
var conn = new SqlConnection(builder.ConnectionString);
conn.Open();
... // queries
conn.Close(); // must close at the end - see a better solution later
Command¶
After establishing the connection to the database, we want to run queries. To do this, ADO.NET provides the IDbCommand interface, which represents a command. The implementations of this interface, such as SqlCommand, just like the connection, are specific to the database server.
Creating the command¶
By setting the following main properties of an IDbCommand we can configure how the given command will be interpreted:
CommandType: there are three types- StoredProcedure
- query the entire table (TableDirect)
- SQL query (Text) - default
CommandText: the text of the command or the name of a stored procedureConnection: database connectionTransaction: the transactionCommandTimeout: timeout for waiting to the result (30 seconds by default)Parameters: parameters to prevent SQL injection attack
Note that the command must specify the connection. Also note, that the transaction is also a property of the command. This is because it is up to the developer to decide whether to consider a particular command as part of a transaction.
Execution¶
Once we have a command object, we execute it. Depending on the expected return value, we can choose from several options (methods on the command object):
ExecuteReader: query multiple recordsExecuteScalar: query a single scalar valueExecuteNonQuery: a query that does not return a result (e.g.,INSERT) - instead, it returns the number of rows affected, e.g., in case of deletion, it is possible to decide whether the operation was successful (whether the record to be deleted was found)ExecuteXmlReader(MS SQL Server): returns an XML document (XmlReaderobject), the result is a single XML field of a record
You can also reuse commands after calling Command.Prepare(). It prepares the command to run on the server-side, but it is only worth it if we run the same statement (possibly with different parameter values).
Sample code for using the command:
// establish the connection
...
var command = new SqlCommand();
command.Connection = connection;
// setting command.Connection is not necessary if we use the connection to instantiate
// the command as: command = connection.CreateCommand()
command.CommandType = CommandType.StoredProcedure;
command.CommandText = "SalesByCategory"; // name of the stored procedure
/* equivalent syntax
var command = new SqlCommand()
{
Connection = connection,
CommandType = CommandType.StoredProcedure,
CommandText = "SalesByCategory"
}*/
// protection against SQL injection
var parameter = new SqlParameter();
parameter.ParameterName = "@CategoryName"; // matches the stored procedures argument name
parameter.SqlDbType = SqlDbType.NVarChar;
parameter.Value = categoryName; // assign value from a C# variable
command.Parameters.Add(parameter);
var reader = command.ExecuteReader();
// see processing the results later
Transactions¶
Transactions in ADO.NET do not need to be initiated with the begin tran SQL statement. ADO.NET provides methods to create and manage the transaction, as shown in the code snippet below. Also, note the using blocks to properly and securely close resources.
// ... creating the connection string
using (var connection = new SqlConnection(connectionString))
{
connection.Open(); // let us not forget this, instantiation does not open the connection
var transaction = connection.BeginTransaction();
// parameter might include a name for the transaction and/or the isolation level
var command = new SqlCommand()
{
Connection = connection,
CommandText = "INSERT into CarTable (Description) VALUES('...')",
Transaction = transaction,
};
try
{
command.ExecuteNonQuery();
// MUST commit a successful transaction
transaction.Commit();
Console.WriteLine("Transaction finished!");
}
catch(Exception commitException)
{
Console.WriteLine("Commit Exception: ", commitException.ToString());
// The rollback below is not necessary. The system performs it automatically
// for any non-committed transaction. The code below is only a possibility.
try
{
transaction.RollBack();
}
catch(Exception rollBackException)
{
Console.WriteLine("Rollback Exception: ", rollBackException.ToString());
}
}
}
Transaction timeout
The total time of all ADO.NET transactions is limited by the setting in the MachineConfig. This is a system-wide setting that applies to all .NET applications running on a system, so it is not a good idea to change this setting. Long-running transactions are to be avoided anyway.
A transaction usually belongs to a single Connection object, but we can also create a transaction involving multiple persistent resource managers (other databases, message queues, anything that supports transactions). At this point, we would be talking about distributed transaction management, which requires an external transaction manager, such as the Microsoft Distributed Transaction Coordinator (MS DTC). Such cases should also be avoided generally.
NULL values¶
How do we know that the result of our query is an empty set? And how do we know that a column contains no value? In .NET we usually check if a value equals null. However, a NULL value in a database is represented differently by ADO.NET depending on the underlying type (int, string, etc.). So how do we check to see if there is a value in the query result?
- If we want to check if the result set of a query contains any records, we can do so by examining the
boolpropertyDataReader.HasRows. - To examine the value of a particular column in the result set, we can use
reader["column name"].IsNullorreader.IsDbNull(index). - And if we want to manually insert a value of
NULLinto a new record, we can use, for example,SqlString.NullorDBNull.Valuein the C# code.
Query result¶
ADO.NET offers two ways of fetching data from a database and working with it: DataReader and DataSet. The main difference between the two solutions is how these use the database connection. These two models are, in general, called: connection-based (DataReader) and connection-less (DataSet) data access. In the connection-based model, the connection to the database is maintained throughout the queries as long as we work with the data. While in the connection-less model modifications are performed in a DataSet, which is synchronized with the database itself (establishing the connection only for the duration of the synchronization). Both options have advantages and disadvantages, which we will discuss in the following sections.
DataReader¶
Here, we need a connection to the database to fetch the required data from the database. The connection remains open only for a short time, during which we query fresh data and usually convert it to some other internal representation.
Processing steps:
- open the connection
- run command(s) to query data
- process the results (typically: convert the data to business entities)
- close the reader
- close the connection
The flow of data using the DataReader is as follows:
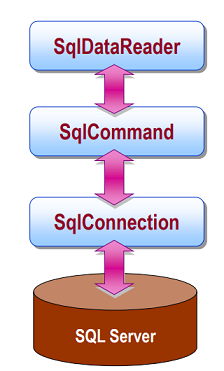
Sample code using a DataReader:
using(var conn = new SqlConnection(connectionString))
{
var command = new SqlCommand()
{
Connection = conn,
CommandText = "SELECT ID, NAME FROM Product"
}
conn.Open();
using(var reader = command.ExecuteReader())
{
while(reader.Read())
{
Console.WriteLine("{0}\t{1}", reader["ID"], reader["Name"]);
// typically rather create a business entity and add it to a list in memory
}
// no need for reader.Close() thanks to the using block
}
// no need for conn.Close() thanks to the using block
}
There are a few things worth paying attention to!
- The value of
reader["ID"]is anobject, not a string or an int. We can usereader.Get***(query_in_column_index)instead, where we must specify the data type (String,Int32, etc.). - If the types are not compatible (e.g., the column is
nvarcharin the database, but we want to read it asint32), we will get a runtime exception. - If there is a
NULLvalue in the database, we will also get a runtime error when using thereader.Get***methods. Instead, we should usereader.IsDBNull(query_in_column_index)to verify, and if it istrue, we can use the appropriatenullvalue instead.
Advantages
- the data is fetched directly from the database; hence, it is up-to-date
- less painful concurrency management, as fresh the data is fetched
- needs less memory (compared to DataSets; see later)
Disadvantages
- needs an open network connection while operations are being performed - thus, it should not be too long
- poor scalability with the number of connections - therefore, the connections should be used only for a short time
DataSet¶
A DataSet can be considered as a kind of cache, or in-memory data storage. We use an adapter (such as SqlDataAdapter) to retrieve data from the database and store it in the Dataset, then we close the connection to the database. We can then make work with the data, even make changes to it within the DataSet, and then update the database with the changes using a new connection. It is worth noting that during the time between retrieval and update anyone can modify the same data in the database, thus the disadvantages of DataSet is having to manage conflicts and concurrent data access issues covered previously in transaction management.
The steps of working with a DataSet:
- Open a connection
- Fill the
DataSetwith part of the database - Close the connection
- Work with the
DataSet(e.g., display and edit in a user interface) - this may take longer - Open a new connection
- Synchronize changes
- Close the connection
The operation of data access in this model using an adapter is shown in the figure below.
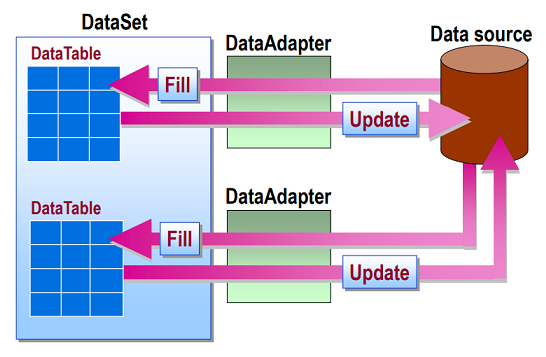
The flow of data using the DataSet is as follows:
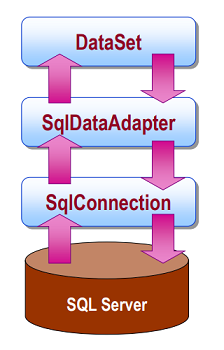
Sample code for working with a DataSet:
var dataSet = new DataSet();
var adapter = new SqlDataAdapter();
// open connection, populate the dataset, close the connection
using(var conn = new SqlConnection(connectionString))
{
adapter.SelectCommand = new SqlCommand("SELECT * FROM Product", conn);
conn.Open();
adapter.Fill(dataSet);
}
-------------------------------------------------------
// working with the data
// typically uinvolves UI; this is just a sample
foreach(var row in dataSet.Tables["Product"].Rows)
{
Console.WriteLine("{0}\t{1}", row["ID"], row["Name"]);
row["Name"] = "new value";
}
-------------------------------------------------------
// at a later point in time, such as after a "Save" button in clicked
// open connection, synchronize data, close connection
using(var conn = new SqlConnection(connectionString))
{
conn.Open();
adapter.Update(dataSet);
//dataSet.AcceptChanges(); -- would only update the dataset, but not the database
}
It is worth noting that the adapter only communicates with the database via Commands. An adapter can use multiple such Commands, so we can even work with multiple Connections towards multiple databases with the same DataSet.
Advantages
- does not need a long-running connection
Disadvantages
- there may be conflicts during saving the changes
- data in the
DataSetmay be stale - has larger memory footprint - the reason why we do not use it in server applications
Risks¶
SQL injection¶
SQL injection is a severe vulnerability in an application when a query is created without sanitizing the values of parameters. Parameter values can come from the client side, with user-selected or user-specified data. This can cause a problem if a malicious user writes an SQL command into a field from which we would expect something else. For example, we would expect a username, but instead Monkey92); DROP TABLE Users; - value is received. If we were to include this text and insert it into our SQL statement, we would also execute drop table, thereby deleting an entire table. This is a serious mistake!
String Interpolation
Do not use C# string interpolation ($"") to build SQL commands. Even if it looks cleaner than string concatenation, it is still vulnerable to SQL injection if the variables contain user input. Always use SqlParameter.
SOLUTION
Using parameters (see the Command section for an example).
Connection string¶
Creating a connection string has a flaw similar to SQL injection. Suppose we ask the user for some kind of data (e.g., username, password). In this case, we do not know exactly what we will get. The connection string consists of key-value pairs and many databases apply the last-wins principle. In practice, this means that if more than one value is specified in a string for the same key, the last one takes effect. That is, if after the username and password a key-value pair is added that already appears in the string before, the new value overwrites the old one. This carries a risk, since a malicious user is able to inject specified parameters into the connection string.
SOLUTION
Using ConnectionStringBuilder (see Connection section).
Connection leak¶
If we do not close all Connections, any time the code containing the not closed connection is executed, we will retrieve a Connection from the pool without returning it. When the pool is emptied, the application will be stuck not being able to talk to the database at all. This is an error that is hard to spot because it "only" happens after the application running for a certain amount of time - and almost never on the developer's machine.
SOLUTION
using block to open the connection, as this will close the connection at the end of the block (see Transaction section example, or DataReader, or DataSet)
A DataReader must be closed in the same way.