Adatvezérelt rendszerek és a többrétegű (háromrétegű) architektúra¶
Mit nevezünk adatvezérelt alkalmazásnak?¶
Minden alkalmazás valamilyen módon adatokat kezel, hiszen a számítógép memóriájában adatok vannak, és a program ezeket manipulálja. De mégse minden alkalmazás adatvezérelt. Akkor hívunk egy alkalmazást adatvezéreltnek, ha a szoftver elsődleges célja a tartalmazott adatok kezelése.
Más szóval, az adatvezérelt alkalmazás azért jön létre, hogy adatokat tároljon, megjelenítsen, manipuláljon. A felhasználó azért lép interakcióba az alkalmazással, hogy az adatokhoz hozzáférjen.
Egy sakkprogram esetében a tábla állása memóriában található adat. De a sakkprogram nem azért jön létre, hogy ezt a memóriabeli táblát manipulálja, hanem azért, hogy a játékos sakkozzon.
Egy adatvezérelt alkalmazásban az adat határozza meg, hogy miként működik a szoftver. Például az adat rekordok egyes attribútumainak függvényében értelmezhető egy törlés művelet a rekordra, vagy sem. Egy hasonló példa, ahol az adat maga határozza meg a rajta végrehajtható műveleteket, a Neptun rendszerben a vizsgajelentkezés. A félévhez tartozó időszakok, beleértve, hogy mikor kezdődik a vizsgaidőszak, maga is a Neptun rendszer adatai között található. Ezen adat határozza meg, hogy a felhasználó (hallgató) tud-e egy vizsgára jelentkezni. Attól, hogy egyik évben máskor kezdődik a vizsgaidőszak, a program logikája (kódja) nem változik meg, a szoftver mégis képes máshogyan viselkedni.
Példa adatvezérelt alkalmazásra¶
A már említett Neptun rendszer egy tipikus adatvezérelt alkalmazás. Célja az oktatáshoz kapcsolódó adatok, a kurzusok, jegyek, vizsgák, stb. kezelése.
Egy másik példa a Gmail: azért létezik, hogy adatokat (itt: emailek, csatolmányok, kontaktok) kezeljen. Az alkalmazás minden funkciója ezen adatok kezeléséről, megjelenítéséről, manipulálásáról szól. Mindemellett, az adatokat hosszú távon megőrzi, azaz minden módosítás a rendszerben megmarad.
Adatvezérelt rendszer felépítése¶
Vegyük a Gmail példáját. Szeretnénk egy olyan modern email rendszert építeni, ahol lehet:
- emaileket küldeni és fogadni,
- van webes és mobil felülete is,
- a felhasználói felület több nyelvet is támogat,
- tudunk fájlokat csatolni
- a csatolmányokat akár Google Drive-ról is tudjuk hivatkozni,
- tudjuk késleltetni egy email elküldését,
- stb.
Gondoljuk végig
Hogyan kezdenénk neki egy ilyen alkalmazás fejlesztésének?
Ez talán túl nehéz kérdés. Kezdjük egy egyszerűbb kérdéssel: tegyük fel, hogy már majdnem minden része működik az alkalmazásnak, csak éppen a késleltetett email küldés hiányzik; ezt hogyan implementálnánk?
Például lehetne úgy, hogy az email küldése gombra kattintásnál elindítunk egy időzítőt, ami 1 perc múlva indítja csak az email küldést. Ez azért nem lesz jó megoldás, mert ha közben bezárjuk a web böngészőt, akkor nem fog az időzítő lejárni, és nem lesz elküldve az email.
Helyette csinálhatjuk úgy, hogy rögzítjük az email mellett, hogy mikor kell elküldeni, így ez az információ is az email, mint kezelt adat része lesz. Ezzel eldöntöttük, hogy nem a felhasználói felület feladata lesz a késleltetett email küldés. Még nem tudjuk, hogy milyen alkalmazás komponensre bízzuk a feladatot, de nem a felhasználó felületre.
Mielőtt meg tudjuk válaszolni a kérdést, hogy mégis milyen komponensnek lesz a dolga az email jövőbeli kiküldése, nézzünk egy hasonló kérdést.
A Gmail az email érkezésének idejét magyar felhasználóknak magyar szokás szerint (pl. "15:23"), más nyelvű felhasználóknak a saját preferenciáik szerint jeleníti meg (pl. "3:23 PM"). Ez azt jelenti, hogy az email, mint adat rekord többféle érkezési idővel rendelkezik? Nyilván nem. Az email érkezési ideje egyetlen dátum, egy univerzális reprezentációban, és csak akkor kerül átalakításra, amikor megjeleníti a felhasználó felület.
Megállapítottuk tehát, hogy vannak feladatok, amelyek a felhasználói felület felelősségi körébe tartoznak, és vannak olyanok, amelyek nem. Így érkezünk meg a többrégetű-, avagy háromrétegű architektúrához.
A többrétegű (háromrétegű) architektúra¶
Adatvezérelt rendszereket tipikusan a többrétegű-, avagy háromrétegű architektúra (three-layered / three-tiered architecture) szerint építünk fel. Jelen kontextusban a két elnevezést szinonimaként kezeljük. Ez az architektúra megkülönbözteti az alkalmazás három fő komponenscsaládját, avagy rétegét:
- a megjelenítési réteget,
- az üzleti logikai réteget,
- és az adatelérési réteget.
Ezen kívül az architektúrához kapcsolódik még:
- az adatbázis, ill. külső adatforrások;
- és az ún. rétegfüggetlen szolgáltatások (lásd később).
Az alkalmazásunkat úgy szervezzük meg, hogy az egyes komponensek (szoftver elemek) rétegekbe szerveződnek, és minden egyes réteg más-más funkcionalitásért felel. Ez a logikai szervezés megkönnyíti a szoftverfejlesztők munkáját azáltal, hogy egyértelmű felelősségi köröket és határokat jelöl ki a rétegekben.
Miért többrétegű, hiszen csak három rétege van
Az elnevezés arra utal, hogy mindegyik réteg maga is tovább bontható további rétegekre az alkalmazás komplexitásának függvényében. Attól többrétegű az architektúra, hogy kettőnél több rétege van. (Így szembeállítva a kétrétegű architektúrával, ahol a felhasználói felület és az üzleti logikai réteg nem válik el.)
Az egyes rétegek nem csak saját felelősségi körrel rendelkeznek, hanem egyben meghatározzák azt az interfészt, amit a ráépülő rétegek használhatnak. Az adatelérési réteg definiálja, milyen műveleteken keresztül érhető el az üzleti logikai réteg számára; az üzleti logikai réteg hasonlóan definiálja az interfészét a megjelenítési réteg felé. Ennek megfelelően minden réteg csak az alatta levővel kommunikál (így tehát a prezentációs réteg nem ad ki pl. SQL lekérdezést az adatbázis felé), valamint a rétegek által definiált interfész mögött az implementáció cserélhetővé válik, így elősegítve az alkalmazás hosszú karbantarthatóságát.
A rétegek szétválasztásának köszönhetően az is gyakori, hogy az alkalmazásunk nem egy helyen, hanem a rétegek mentén több kiszolgálón fut. Leggyakoribb esete ennek a megjelenítési réteg leválasztása, amely például egy webalkalmazás esetén a felhasználó számítógépén a böngészőben fut, míg a többi komponens a távoli kiszolgálón található. Hasonlóan gyakori, hogy az adatréteg (pl. adatbázis) egy saját kiszolgálót kap teljesítmény okokból. Amíg a rétegek közötti interfészek változatlanok maradnak, a rétegek akár kiszolgálók között is mozgathatóak. Ennek tipikus oka a teljesítmény-optimalizálás és a nagy terhelések kiszolgálásának elősegítése (pl. forgalmas webhelyek esetében).
Layer / tier
Az architektúra angol elnevezése megkülönbözteti a logikai és fizikai elválasztást. A three-layered elnevezésben a rétegek logikailag különválnak, de azonos kiszolgálón futnak. A three-tiered azonban a rétegek (tier) mentén fizikai elválasztására, külön kiszolgálókon való futásra is utal.
Egy jó architektúrával rendelkező alkalmazás hosszú életciklusa során is karbantartható marad. A rétegezés nem plusz teherként, betartandó szabályok halmazaként, hanem mankóként segíti a fejlesztőket a kód fejlesztésében. Ezért egy többrétegű alkalmazás fejlesztése során fontos, hogy pontosan értsük, mely rétegek milyen felelősségekkel rendelkeznek, és milyen feladatok tartoznak hozzájuk.
A réteges felépítés nem azt jelenti, hogy a felhasználók által használt funkciók csak egy-egy rétegben jelennek meg. A legtöbb funkció valamilyen módon az összes rétegben megjelenik: a funkcióhoz tartozik felhasználói felület, valamilyen adatkezelés az üzleti logikában, és az eredmény mentésre kerül az adatbázisba.
A többrétegű architektúrával készülő alkalmazások kód szervezése is tükrözi a rétegek felépítését. Az adott programozási környezet lehetőségeit és szokásait figyelembe véve az egyes rétegeket külön projektekbe, csomagokba szokás elhelyezni. Ez egyértelművé teszi az egymásra épülést is, hiszen a projektek és csomagok között általában csak egyirányú hivatkozás lehetséges (tehát ha az üzleti logikai csomag használja az adatelérési réteget, akkor fordítva ez már nem történhet meg).
A többrétegű architektúra nem az egyetlen lehetőség adatvezérelt alkalmazás megvalósítása esetén. Kis, egyszerű alkalmazásokra célszerű lehet a kétrétegű architektúra, míg sokkal komplexebb rendszerek esetén az alkalmazás további darabolása is szükséges lehet például ún. mikroszolgáltatások architektúra irányába lépve.
A többrétegű architektúra rétegeinek felelőssége¶
Vizsgáljuk meg alaposabban a rétegeket, és feladataikat, felelősségeiket. Az architektúra részletesebben kifejtve az alábbi elemeket tartalmazza.
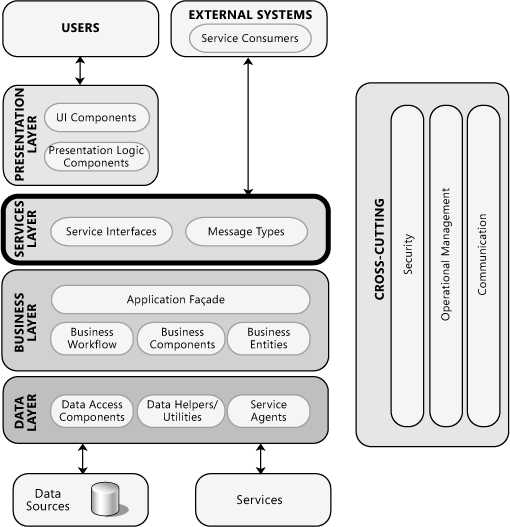
Forrás
Microsoft Application Architecture Guide, 2nd Edition, https://docs.microsoft.com/en-us/previous-versions/msp-n-p/ee658109%28v%3dpandp.10%29
A rétegeken "lentről felfelé" haladunk végig.
Az adatforrások¶
A leggyakoribb adatforrás az adatbázis. Ez lehet relációs, vagy akár NoSQL adatbázis is. Feladata az adataink hosszú távon megmaradó és megbízható (ún. "perzisztens") tárolása. Tipikusan ez az adatbázis egy megbízható gyártótól származó szoftver, amely egy külön erre a célra üzemeltetett kiszolgálón fut, így az adatelérési réteg hálózaton keresztül éri el.
Előfordulhat az is, hogy a rendszer által kezelt adatok nem mind a saját adatbázisunkban találhatóak, hanem olyan más külső szolgáltatásokban, amelyeket "adatbázisként" használunk. Például a Gmail esetén fájl csatolmányok tárolhatóak az emailekkel együtt egy adatbázisban, de lehetőségünk van Google Drive-ról is csatolni fájlokat. A Gmail ilyenkor a Google Drive-ról letölti az elérhető fájlok listáját, hogy a felhasználó kiválassza a csatolandó mellékletet. A Google Drive nem adatbázis, mégis, a használat szempontjából adatforrásként működik.
Az ilyen jellegű külső szolgáltatásokat azért az adatbázisok mellett helyezzük el képzeletben, mert a mi alkalmazásunk számára csak adatokat szolgáltatnak (pl. listázd az elérhető fájlokat). A belső működésükbe nem látunk bele, és nem is célunk azt megérteni. Ilyen szempontból nem nagy a különbség egy relációs adatbázis és egy külső szolgáltatás között.
Ma már több modern adatbázis-kezelő rendszer is gyakran rendelkezik a külső szolgáltatások eléréséhez használt HTTP/REST-jellegű interfésszel, és nem SQL nyelven kell velük kommunikálni. Így egyre kevesebb a különbség egy adatbázis és egy külső adatforrás között.
Adatelérési réteg¶
Az adatelérési réteg (data access layer, röviden DAL) feladata az adatforrások kényelmes elérésének biztosítása. Fő funkciója az elemi adatszolgáltatási műveletek biztosítása, mint egy új rekord tárolása, meglevő módosítása vagy törlése.
Az adatforrásokat és az adatelérési réteget szokás még egyben adatrétegnek (data layer) is nevezni.
Az adatbázisok eléréséhez szükséges funkcionalitásokat az ún. data access components-ek valósítják meg. Céljuk, hogy elrejtsék a komplexitást, ami az adatbázis kezeléséből adódik, és központilag kényelmes, a felsőbb réteg számára egyszerűen használható szolgáltatásként nyújtsák az adattárolást. Ide tartozik például az SQL parancsok kezelése, valamint az adatbázis tárolási modelljének leképzése az üzleti logika számára is kényelmesen használható módon.
Amennyiben az adatok nem egy adatbázisban, hanem egy külső szolgáltatásban találhatóak, a service agent-ek feladata a külső rendszerrel való kommunikáció kezelése.
Ebben a rétegben található komponensek általában egy konkrét technológia köré csoportosulnak, például a választott adatbázis-kezelő rendszer eléréséhez használt technológia (mint az ADO.NET, Entity Framework, vagy JDBC, JPA, stb.). Az itt megvalósított logikák gyakran szorosan csatolódnak az adatkezelési technológiákkal. Fontos azonban, hogy ez a platform specifikusság ne szivárogjon ki ebből a rétegből.
Fontos
Egy jól megtervezett rendszerben SQL lekérdezések csak az adatelérési rétegben jelennek meg, a többi réteg semmilyen körülmények között nem állít össze SQL lekérdezést.
Mivel az adatbázisban való tárolás gondolkodásmódja (tipikusan a relációs séma), valamint az objektumorientált modellezés nem egy az egyben fedik egymást, ezért ennek a rétegnek a feladata a két világ közötti leképezés és megfeleltetés megvalósítása. A relációs adatbázisokban használt külső kulcsokat (foreign key) objektumorientált asszociációkra, kompozíciókra alakítjuk, valamint ha szükséges, konvertálást végzünk a különböző rendszerek által támogatott adattípusok között. Erről a feladatról a későbbiekben még részletesebben ejtünk szót.
A külső rendszerekkel való kommunikáció, akár egy adatbázis-kezelő rendszerről, akár egy külső szolgáltatásról van szó, sajátos kezeléstechnikát igényel. Teljesítmény szempontjából nem mindegy, hogy a távoli kiszolgáló megszólítása, a kapcsolat felépítése mikor és milyen gyakran történik. Egyes kapcsolatfelvételi módok, mint például a HTTP (és alatta a TCP) kapcsolat felépítése tipikusan egyszerű és gyors; míg egy relációs adatbázis szerverhez történő csatlakozás hosszabb folyamat. Így az adatelérési réteg felel azért is, hogy megfelelő módon kezelje a kapcsolatokat, és ha lehetséges, újra használja a kapcsolatokat (connection pooling). Ezt a működést általában a jól megválasztott kliens könyvtárak automatikusan biztosítják is.
Hasonlóan réteg specifikus feladat az adatok konkurens elérésének és módosításának kezelése. Ezzel részletesen foglalkozunk később. Egyelőre annyit érdemes megjegyezni erről, hogy a többrétegű alkalmazást tipikusan egyszerre több felhasználó használja (gondoljunk csak bele a Neptun rendszerbe, vagy egy webshop működésébe), így előfordulhat, hogy egyszerre többen módosítanának a rendszerben. Ennek szabályait, hogy milyen módosítások engedélyezettek, és mik nem, a konkurenciakezelés témakörében fogjuk tárgyalni.
Üzleti logikai réteg¶
Az üzleti logikai réteg adja az alkalmazásunk lelkét. Az adattárolás, az adatelérés, és a megjelenítés is mind azért születik, hogy az üzleti logikai rétegben lefektetett funkcionalitásokat nyújtani tudjuk.
Hogy pontosan milyen funkciókat nyújt ez a réteg, annak függvényében alakítjuk ki, hogy milyen alkalmazásról van szó. Ha a Neptun rendszert tervezzük, akkor vizsgajelentkezésről, tárgyfelvételről, tanulmányi időszakokról fog szólni a réteg; ha egy webshopot tervezünk, akkor termékek, keresés, értékelés, vásárlás lesz a középpontban.
Általánosan ebben a rétegben
- üzleti entitások (business entities),
- üzleti komponensek (business components),
- és üzleti folyamatok (business workflows) találhatóak.
Az entitások hordozzák a kezelt információkat. A problématerület függvényében olyan entitásokat definiálunk, mint a termék és értékelés (egy webshopban), vagy a kurzus és a vizsga (a Neptunban).
Az entitások manipulálásáért felelnek a komponensek. Ezek olyan alapszolgáltatásokat implementálnak, amelyek az alkalmazásunk által megvalósított bonyolult funkciók alap építőköveit adják. Ilyen funkció lehet például a termékek listázása, vagy a név alapján történő keresés.
Ezen alap funkciókból építjük fel a folyamatokat. A folyamatok a végfelhasználó számára fontos műveleteket fogják össze. Egy folyamat általában több komponens több műveletét használja. Ilyen folyamat például a rendelés véglegesítése (checkout) egy webshopban, amely ellenőrzi a termékeket, kiállítja a számlát, elküldi a megerősítést emailben, stb.
Szolgáltatási interfész alréteg¶
A fenti ábrán megkülönböztetésre került a services alréteg. Ezt az üzleti logikai réteg részének tekintjük, annak legfelső alrétege. Feladata a külső hívó számára interfészt biztosítani az üzleti logikai réteg funkcionalitásának eléréséhez.
Minden eddig tárgyalt réteg ugyanígy biztosít egy interfészt a felsőbb rétegek számára. Az üzleti logikai réteg azért speciális, és azért szokás ezt a szolgáltatási interfész alréteget külön megemlíteni, mert manapság gyakran nem is egyetlen ilyen interfészt publikálnak az alkalmazások. Gyakori, hogy egy alkalmazás több megjelenítési réteggel is rendelkezik, gondoljunk csak bele a Gmail esetébe: webalkalmazás, és sok féle mobil platform. Mindegyik felhasználói felület hasonló, de nem teljesen azonos szolgáltatást nyújt, így gyakran elkülönülnek a különböző megjelenítési rétegek számára nyújtott interfészek.
További gyakori eset, hogy az alkalmazásunk nem csak egy saját megjelenítési réteggel rendelkezik, hanem ún. API-t (application programming interface) is elérhetővé tesz. Az API harmadik fél számára teszi elérhetővé az alkalmazásunk funkcióit. A saját felhasználói felületünk, és a harmadik fél számára nyújtott API funkcionalitása és elérése gyakran eltérő, és külön technológiát, így külön szolgáltatási interfészeket is igényel.
Az API publikálással válhat a mi alkalmazásunk maga is külső adatforrássá más alkalmazások számára.
Az üzleti logikai funkcióink publikálásával részletesebben foglalkozunk a félév során. Meg fogjuk ismerni a web services és a REST modelleket.
Megjelenítési réteg¶
A megjelenítési réteg (presentation layer, UI, vagy felhasználói felület) feladata az adatok felhasználóbarát megjelenítése, és a lehetséges műveletek kezdeményezésének lehetővé tétele.
Az adatok prezentálása olyan módon kell történjen, ahogy az a felhasználó számára hasznos. Például egy listás megjelenítés esetén gyakran a felhasználói felület feladata a rendezés, csoportosítás, kereshetőség.
Rendezés és keresés
A választott technológia függvényében a rendezés, keresés tipikusan igénybe veszi a többi réteget is. Nagy mennyiségű adat, több száz, vagy több ezer rekordot nem célszerű egyben eljuttatni a megjelenítési réteg számára, hogy ott legyen a keresés megvalósítva. Ez egyrészt terheli a hálózatot is, másrészt a UI technológiák limitációi miatt nem hatékony sok adatot itt memóriában tartani. Viszont, ha nem nagy mennyiségű adatról van szó, sokkal elegánsabb a megjelenítési rétegre bízni mindezt, mert sokkal gyorsabb lesz a visszajelzés a felhasználónak (hiszen ha mindezt a UI végzi, nem szükséges minden alkalommal a háttérrendszerhez fordulni).
Az adatok megjelenítése során a UI felelős olyan egyszerű transzformációkért is, mint például a dátum felhasználóbarát megjelenítése. A korábban említett példa alapján tehát egy dátumot a felhasználói felület feladata a "15:23", 3:23 PM", vagy akár a "15 perccel ezelőtt" szöveges megjelenítésre átalakítani.
Továbbá, a felhasználói felület feladata az ún. lokalizáció is. A lokalizáció a UI felhasználó által választott nyelven való megjelenítése, amely kiterjed a statikus szövegekre, feliratokra is, de egyben a kultúra függő adat transzformációkra is (mint a dátumok, számok, pénznemek megjelenítése is).
A felhasználói felület felel még a végfelhasználó interakcióinak kezeléséért. Ha egy gombra kattintottak, akkor a UI kezdeményezi a kért funkció végrehajtását, és tájékoztatja a végeredményről a felhasználót.
Amikor a felhasználó adatot visz be a rendszerbe, azt is a felhasználói felület biztosítja, és ez a réteg felel az adatok validációjáért (ellenőrzéséért) is. A validáció során egyszerűbb ellenőrzések hajthatók végre, mint például, hogy a szükséges mezők nem maradhatnak üresen, az email címben kell legyen @ karakter, a megadott percnek 0 és 59 közé kell esnie, stb.
Validáció
A validációt nem elég, ha kizárólag a felhasználói felület végzi. A választott technológiától függően a UI könnyen "kikerülhető", és lehetőség van az adatokat közvetlenül a háttérrendszernek küldeni. Ilyen esetben, ha a validációt csak a felhasználó felület valósítaná meg, érvénytelen adat kerülhetne a rendszerbe. Ezért a validációkat tipikusan megismétli a háttérrendszer is. Ennek ellenére praktikus ezeket a felhasználói felületen is elvégezni, mert azonnali visszajelzést tudunk így adni a felhasználónak.
A réteggel ennél részletesebben nem foglalkozunk ezen tárgy keretei között.
Rétegfüggetlen szolgáltatások¶
Rétegfüggetlen szolgáltatások (crosscutting concerns) néven szoktuk hivatkozni az alkalmazás olyan szolgáltatásait, amelyek nem csak egy rétegben jelennek meg. Az ilyen szolgáltatások implementálásakor igyekszünk elérni, hogy bár több rétegben is jelen van az adott szolgáltatás, mégis, egy közös implementációt, kódot, megoldást használjunk.
Biztonság¶
A biztonsági szolgáltatások lefedik
- a felhasználók beléptetését (autentikáció)
- és a hozzáférés ellenőrzését (autorizáció),
- valamint a nyomkövetést és auditálást.
Az autentikáció a "ki vagy" kérdést, míg az autorizáció a "mihez van jogod" kérdést kezeli.
Az autentikáció nem csak a felhasználói felületen történő bejelentkezést jelenti. Az adatbázis szerverek felé is tipikusan szükségünk van bejelentkezésre, vagy ha külső szolgáltatás felé fordulunk, oda is be kell jelentkeznünk. Ezért tehát ez az aspektus több rétegben is jelen van.
Bejelentkezésre többféle megközelítést választhatunk. Készíthetünk saját bejelentkezést, használhatunk valamilyen címtáras megoldást, vagy OAuth bejelentkezést. Ha a mi alkalmazásunk bejelentkeztetett egy felhasználót, akkor eldönthetjük, hogy a külső szolgáltatás felé ennek a felhasználónak a nevében fordulunk (pl. ahogy a Gmail a Google Drive-ról származó fájlokat a bejelentkezett felhasználó számára listázza), avagy egy központi felhasználó nevében járunk el (pl. ha a rendszer emailt küld, akkor azt tipikusan egy központilag konfigurált fiók nevében küldi el).
A hozzáférés szabályozás megszabja, hogy milyen funkciókhoz ki férhet hozzá. Ennek ellenőrzése történhet a felhasználói felületen is (ne is jelenjen meg a nem elérhető funkció), de ahogy a bemenetek validációjánál is említésre került, az üzleti logikának meg kell ismételnie az ellenőrzést. Fontos, hogy ez a két validáció azonos szabályrendszer szerint dolgozzon.
A nyomkövetés, auditálás feladata, hogy visszakereshetővé váljon a rendszerben, hogy ki, mikor, mit csinált. Célja, hogy egy ember ne tudja "eltüntetni a nyomokat". Ez a fajta naplózás több ponton is megtörténhet, tipikusan az üzleti logikában és az adatbázisban.
Üzemeltetés¶
Az üzemeltetési szempontok figyelembe vétele elősegíti, hogy a szoftver fejlesztés utáni életciklusa során is kielégítse a felhasználók igényeit. Ide olyan feladatok megoldása tartozik, mint az egységes kivételkezelés, a megfelelő naplózás és monitorozás, valamint a konfigurálás és konfiguráció-kezelés.
A kivételkezelés során egy olyan egységes módszert kell kialakítani, ami az alkalmazás futása során keletkező minden kivételt megfog. Mindenképpen rögzíteni kell a hibákat (pl. naplózással), és emellett a felhasználót is valamilyen módon tájékoztatni a hiba jellegéről (pl. hogy próbálja-e újra a műveletet, vagy várjon a javításig). Az egységes kivételkezelés azért nagyon fontos, mert az architektúra alsóbb rétegeiben előforduló hibákat az üzemeltetés és fejlesztés nem látja, csak ha azok megfelelően kezelve és rögzítve lesznek.
A naplózás és monitorozás az üzemszerű és nem rendeltetésszerű viselkedés követéséhez is fontos. A naplózás általában szöveges formátumú rendszer üzenetek rögzítését jelenti. A monitorozás a rendszer állapotát meghatározott jellemzők (ún. KPI-k, key performance indicator) követését jelenti. Ilyen KPI lehet a memória fogyasztás, a hibás kérések száma, a kiszolgált felhasználók száma, stb.
A konfiguráció kezelés pedig arról szól, hogy az alkalmazás működését befolyásoló beállításokat hol tároljuk, és hogyan kötjük be őket az alkalmazásba. Konfigurációnak minősülnek kiszolgálók elérési útvonalai (pl. az adatbázis szerver címe), de akár a megjelenítési rétegben használt háttérszín is. Alapelv, hogy a beállításokat minél kevésbé "égessük be" a forráskódba, hogy alkalmazkodni tudjunk az üzemeltetés során előforduló különböző környezetekhez. A konfiguráció történhet tipikusan konfigurációs fájlokkal, vagy kifejezetten konfiguráció-menedzsment célra szolgáló eszközökkel is.
Az üzemeltetési aspektusokkal nem fogunk részletesebben foglalkozni. Tipikusan a választott platform képességeit és lehetőségeit használjuk a megvalósításhoz.
Kommunikáció¶
A kommunikációs szolgáltatás az egyes rétegek közötti kommunikációs forma megválasztásáért és kezeléséért felel. Ennek helyes megválasztása nem csak architekturális kérdés, mert nagyban függ a telepítés mikéntjétől is. Amennyiben az egyes rétegek eltérő kiszolgálón kerülnek elhelyezésre, hálózati alapú kommunikációra van szükség; míg azonos kiszolgálón üzemeltetett komponensek között egyszerűbb megoldásokat használhatunk.
Manapság szinte minden alkalmazásban valahol megjelenik a hálózati kommunikáció: tipikusan az adatbázis és adatforrások irányába, illetve a megjelenítési réteg és a szolgáltatási interfészek között. Itt tipikusan HTTP vagy arra épülő kommunikációt szoktak alkalmazni, bár nagyobb teljesítményt igénylő alkalmazások esetén érdemes lehet TCP alapú bináris kommunikációt választani. Nagy rendszerek esetén, ahol az egyes rétegek maguk is elosztva, több kiszolgálón találhatóak, pedig gyakori az üzenetsorok (message queue) használata.
A kommunikáció részének tekintjük általában a titkosítást is. Amennyiben az egyes rétegek külön kiszolgálókon futnak, fontos, hogy megfelelően titkosítsuk a kommunikációt. A felhasználói felület és a szolgáltatási interfészek között ez általában HTTPS/TLS kommunikációt jelent.
Backend és frontend¶
Ha az alkalmazásra egy kicsit más szemszögből nézünk, akkor meg szoktuk különböztetni a backend és a frontend részt. A frontend nagyrészt a felhasználói felület, vagyis a prezentációs réteg, ill. annak változatos megjelenési formái (böngészőben futó webalkalmazás UI, natív mobil alkalmazás, vastag kliens UI, stb). A felhasználó ezzel lép kapcsolatba. A backend pedig a "háttérben" futó rendszer, a szolgáltatási API-k, az üzleti logikai réteg, az adatelérés, adatbázisok.
A frontend nem csak felhasználó számítógépén jelenik meg. Frontend technológia függvényében gyakran előfordul, hogy a felhasználói felület egy részét a backend készíti el. Ezt szokták szerver oldali renderelésnek hívni.
Ha összefoglalóan akarjuk hivatkozni, akkor a tárgy keretében a backend technológiákkal foglalkozunk.
Ellenőrző kérdések¶
- Mik a háromrétegű architektúra rétegei? Mik a felelősségeik?
- Ismertesse a rétegfüggetlen szolgáltatásokat!
- Döntse el, hogy igaz vagy hamis az alábbi állítás:
- Az adatbevitel validációjáért csak a megjelenítési réteg felel.
- Az architektúra szempontjából helytelen, ha SQL parancsok kerülnek az üzleti logikai rétegbe.
- A háromrétegű architektúra rétegei mindig külön kiszolgálókon futnak.
- A háromrétegű architektúra akkor lesz többrétegű, pl. négyrétegű, ha teljesítmény okokból az üzleti logikai réteget más kiszolgálóra visszük, mint az adatelérési réteget.
- A réteges felépítés garantálja, hogy a rétegek által biztosított szolgáltatásokat tetszőlegesen megváltoztathatjuk, ez nem érinti a többi réteget.
- A frontend és a megjelenítési réteg egy és ugyanaz.
- Kivételkezelésre csak az üzleti logikai rétegben van szükség.