Query optimization¶
We will examine the query optimization behavior of Microsoft SQL Server. To properly understand the optimizer's behavior, in the first 5 exercises, we will explain the queries and the behavior too. The rest of the exercises is individual work where it is your task to infer the reason for a specific plan. Your task is to document the behavior and submit the documentation of all exercises.
Pre-requisites and preparation¶
Required tools to complete the tasks:
- Windows, Linux, or macOS: All tools are platform-independent, or a platform-independent alternative is available.
- Microsoft SQL Server
- The free Express version is sufficient, or you may also use localdb installed with Visual Studio
- A Linux version is also available.
- On macOS, you can use Docker.
- Visual Studio Code or any other tool for writing markdown
- SQL Server Management Studio, or you may also use the platform-independent Azure Data Studio is
- Database initialization script: mssql.sql
- GitHub account and a git client
Materials for preparing for this laboratory:
- Markdown introduction and detailed documentation
- Using Microsoft SQL Server: description
- The schema of the database
- Microsoft SQL Server query optimization
- Check the materials of Data-driven systems
Initial steps¶
Keep in mind that you are expected to follow the submission process.
Create and check out your Git repository¶
-
Create your git repository using the invitation link in Moodle. Each lab has a different URL; make sure to use the right one!
-
Wait for the repository creation to complete, then check out the repository.
Password in the labs
If you are not asked for credentials to log in to GitHub in university computer laboratories when checking out the repository, the operation may fail. This is likely due to the machine using someone else's GitHub credentials. Delete these credentials first (see here), then retry the checkout.
-
Create a new branch with the name
solutionand work on this branch. -
Open the checked-out folder and type your Neptun code into the
neptun.txtfile. There should be a single line with the 6 characters of your Neptun code and nothing else in this file.
Open the markdown file¶
Create the documentation in a markdown file. Open the checked-out git repository with a markdown editor. We recommend using Visual Studio Code:
-
Start VS Code.
-
Use File > Open Folder... to open the git repository folder.
-
In the folder structure on the left, find
README.mdand double click to open. -
Edit this file.
-
When you create a screenshot, put the file in this directory next to the other files. This will enable you to use the file name to include the image.
File name: lowercase English alphabet only
You should avoid using special characters in the file names. Best if you use the English alphabet and no spaces either. The various platforms and git handle filenames differently. GitHub's web interface will only render the documentation with the images correctly if you only use all lowercase filenames with the English alphabet and no spaces.
-
For convenient editing open the preview (Ctrl-K + V).
Alternative editor
If you do not like VS code, you can also use the GitHub web interface to edit the markdown; you also have a preview here. File upload will be trickier.
Create the database¶
-
Connect to Microsoft SQL Server using SQL Server Management Studio. Start Management Studio and use the following connection details:
- Server name:
(localdb)\mssqllocaldbor.\sqlexpress(which is short for:localhost\sqlexpress) - Authentication:
Windows authentication
- Server name:
-
Create a new database (if it does not exist yet). The name should be your Neptun code: in Object Explorer right-click Databases and choose Create Database.
-
Create the sample database by executing the initializer script Open a new Query window, paste the script into the window, then execute it. Make sure to select the correct database in the toolbar dropdown.

-
Verify that the tables are created. If the Tables folder was open before, you need to refresh it.
 .
.
Getting the actual execution plan¶
If you are not using Windows
We are primarily using SQL Server Management Studio to get the execution plans. If you are not using Windows, you can also use Azure Data Studio-t to obtain the query plan.
We will check the query plan the optimizer chose and the server executed in the following exercises. In SQL Server Management Studio, open the Query menu and check Include Actual Execution Plan.
The plan will be displayed after the query is completed at the bottom of the window on the Execution plan pane.
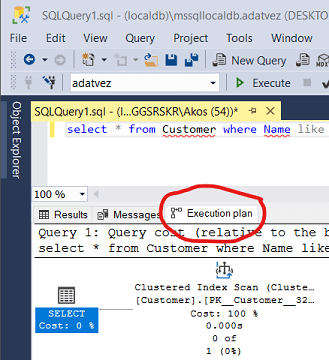
The plan is a data flow diagram where the query execution is the flow of the data. The items are the individual steps, and the percentages are the relative cost of each step with regards to the whole query.
Exercises solved together¶
SUBMISSION
The submission shall be a documentation written in the README.md file:
- document the SQL commands (if the exercise tells you to),
- a screenshot of the query plan (just the plan and not the entire desktop!),
- and an explanation: what do you see on the query plan and why the system chose this option.
The documentation should correctly display with the images in the web interface of GitHub! You need to verify this during the submission: open the repository in the browser and switch to your branch; GitHub will automatically render the README.md file with the images.
Submit your own work
Even though the solutions are provided below, you are required to execute the queries, get the execution plan, think about it, and document it with your own words. Copying the explanations from below is not acceptable!
If the query plan or the explanation of subsequent exercises is the same, or at least very similar, it is enough to document everything once (one screenshot and one reasoning); and list which (sub)exercises it is the solution for.
Exercise 1 (2p)¶
Drop the CustomerSite => Customer foreign key and the Customer table primary key constraint. Find these in the Object Explorer and delete them (the PK... is the primary key while the FK... is the foreign key - the ones you need to delete are in two different tables!):

Execute the following queries on the Customer table and examine the execution plans (always fetch the entire records using select *):
- a) query the whole table
- b) get one record based on primary key
- c) querying records where the primary key is not a specified constant (use the
<>comparison operation for not equals) - d) querying records where the primary key is greater than a specified constant
- e) querying records where the primary key is greater than a specified constant, ordering by ID descending
Document the SQL commands you used and explain the actual query execution plan!
Solution
The SQL queries:
- a)
select * from customer - b)
select * from customer where id = 1 - c)
select * from customer where id <> 1 - d)
select * from customer where id > 1 - e)
select * from customer where id > 1 order by id desc
a)-d)
The execution plan is indentical for all, it uses a table scan each time:
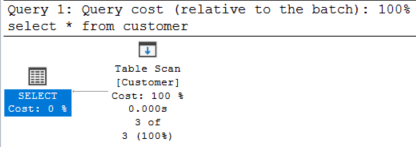
Explanation: the optimizer cannot use any index, as there is none. Thus there is no other choice but to use a table scan.
e)
This one is a little different due to the order by there is a sort stage too.

Explanation: The table scan is the same, and after that, there is still a need for sorting - without any index, it is a separate stage.
Exercise 2 (2p)¶
Re-create the primary key of the Customer table:
- Right-click the table > Design > then right-click the ID column "Set Primary Key " then Save,
- or execute
ALTER TABLE [dbo].[Customer] ADD PRIMARY KEY CLUSTERED ([ID] ASC)
Re-run the same queries as in the previous exercise. What do you experience?
Solution
The commands are the same as before.
a)

The Clustered Index Scan iterates the table. We have a Clustered Index automatically created for the primary key, which has the records sorted by ID. By iterating through this index, all records are visited. This is almost identical to a Table Scan, though, not efficient. However, this is what we asked for here.
b)

A Clustered Index Seek is enough. Since the filter criteria is for the ID, for which there is an index available, the matching record can be found quickly. This is an efficient plan; the Clustered Index is used for the exact purpose we created it for.
c)
Similar to the previous one, a Clustered Index Seek between two intervals (< constant, > constant). Since the filter criteria still references the ID field with a Clustered Index, the query will use this index. This is an efficient query.
d)
Very similar to the previous one with a range filter.
e)
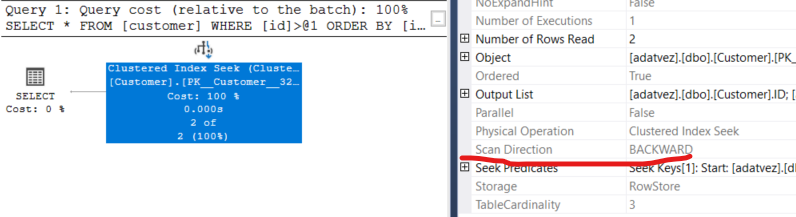
Clustered Index Seek with a backward seek order. The Properties window shows the Seek Order-t: find the last matching record, and walk the index backward, which will yield a sorted result set.
Exercise 3 (2p)¶
Execute the following queries on the Product table.
- f) query the whole table
- g) search for specific records where
Priceequals a value - h) query records where
Priceis not a specified constant (<>) - i) query records where
Priceis greater than a value - j) query records where
Priceis greater than a value, ordered byPricedescending
Document the SQL commands you used and explain the actual query execution plan!
Solution
The SQL commands:
- f)
select * from product - g)
select * from product where price = 800 - h)
select * from product where price <> 800 - i)
select * from product where price > 800 - j)
select * from product where price > 800 order by price desc
f)-i)

A Clustered Index Scan iterates through the contents of the index. This is still equal to reading the entire table since there is no index to match the filter criteria. Although a Clustered Index is used, it does not serve any purpose in filtering; all records are visited, and the filter is evaluated for each. These are not efficient queries, as the existing index is of no use.
j)
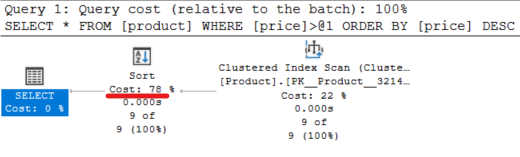
Still a Clustered Index Scan, but what is interesting is that cost of the sorting stage is quite large. Even after executing a costly Index Scan, we still have further sorting to do. A good index would help, but there is no index for the sorted column.
Exercise 4 (2p)¶
Add a new non-clustered index on column Price. How do the execution plans change?
To add the index use Object Explorer, find the table, expand it, and right-click Indexes -> New index > Non-Clustered Index...

Indices should have meaningful names, e.g., IX_Tablename_Fieldname. Add Price column to the Index key columns list.

Repeat the queries from the previous exercise and explain the plans!
Solution
The SQL commands are the same as in the previous exercise.
f)
Despite the new index, it is still an Index Scan - since we asked for the contents of the entire table.
g)-i)
Clustered Index Scan iterating through the entire table, just as if there was no index available for the filtered column.
Why does it not use the new index? The reason is the projection; that is, we query the entire record. The NonClustered Index could yield a set of record identifiers, after which the records themselves would still need to be queried. The optimizer decides that it is not worth doing so; an Index Scan is more efficient.
j)

The NonClustered Index Seek yields keys, which are looked up in the Clustered Index, just like joining the two indices.
We would have expected something similar in the previous queries too. The Clustered Index is needed as entire records are fetched as the NonClustered Index only provides references. However, these references are in the correct order (the NonClustered Index ensures it); so after the lookup in the Clustered Index, there is no further need to do the sorting. If only the Clustered Index were used (Clustered Index Scan), the sorting would have to be performed in a separate stage. This is an acceptable query, as the NonClustered Index helps in avoiding a costly sorting step.
Exercise 5 (2p)¶
Generate new records into the Product table with the script below. How do the execution plans change?
When repeating the query for sub-exercise i), choose a constant value that will yield few resulting records, then choose a value that returns almost all records. Explain the differences!
SELECT TOP (1000000) n = ABS(CHECKSUM(NEWID()))
INTO dbo.Numbers
FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX n ON dbo.Numbers(n)
;
INSERT INTO Product(Name, Price, Stock, VATID, CategoryID)
SELECT 'Apple', n%50000, n%100, 3, 13
FROM Numbers
Solution
The SQL commands are the same.
f)
Same as before.
g)

References from the NonClustered Index Seek are looked up in the Clustered Index, just like joining the two indices.
Let us compare this plan to the one from before having a smaller table. Why is the Clustered Index Scan not used now? In the case of larger tables, the selectivity (i.e., how many records match the filtering) is more important, hence the use of the NonClustered Index. The Clustered Index Scan would be too costly in a large table. The NonClustered Index can reduce the number of records, hence its role here. Based on the statistics of the Price column, it can be derived that the = operator will match few records. Important! Just because it is an = comparison, it does not directly follow that there are few matches; imagine the column having the same value in all records. Hence the need for the statistics!
This is an acceptable query. Since the filtering reduces the number of records, it is worth using the index.
h)

Clustered Index Scan as before.
Why the difference compared to the previous case? If the = operator yields few matches, then <> will yield many. This is derived from the statistics too. So no use in doing the same as in the previous case; a Clustered Index Scan is probably more efficient.
i)
The plan depends on the constant. If it yields few matches, similar to g); otherwise the same as in h).
j)
Just like for g). Does the order by desc matter here? The optimizer tries to avoid sorting, and this is the only way to do so. This is an acceptable plan; by using the NonClustered Index there is no separate sorting stage.
Individual exercises¶
SUBMISSION
Continue documenting the results the same way.
Keep in mind that the documentation should correctly display with the images in the web interface of GitHub! You need to verify this during the submission: open the repository in the browser and switch to your branch; GitHub will automatically render the README.md file with the images.
Exercise 6 (1p)¶
Repeat the queries on the Product table, but instead of fetching the entire record, only get the ID and the Price columns. How do the execution plans change? Explain the differences!
Exercise 7 (1p)¶
Analyze the following queries executed on the Product table:
- k) query records where the primary key is between two values (use the
BETWEENoperator) - l) query records where the primary key is between two values (use the
BETWEENoperator), or it is equal to a value that falls outside of this range
Document the SQL commands you used and explain the actual query execution plan!
Exercise 8 (1p)¶
In exercise 6, WHERE Price= compared an integer and a floating-point number. Let us experiment with other comparisons: query records from the Product table with the following filter criteria.
- m)
where cast(Price as int) = integer number - n)
where Price BETWEEN integer number-0.0001 AND integer number+0.0001
Choose a random integer number in these queries and fetch only the primary key. Analyze the execution plans.
Exercise 9 (1p)¶
Analyze the following queries execute on the Product table:
- o) query entire records where
Priceis less than a constant value (the filter should yield few matches), ordered by ID descending - p) the same, but fetch only
IDandPrice - q) query entire records where
Priceis greater than a constant value (the filter should yield many matches), ordered by ID descending - r) the same, but fetch only
IDandPrice
Document the SQL commands you used and explain the actual query execution plan!
Exercise 10 (1p)¶
Create a new index for the Name column and analyze the following queries executed on the Product table:
- s) query names and IDs where the name begins with B - use function
SUBSTRING - t) the same, but now using
LIKE - u) query names and IDs where the name contains a B (LIKE)
- v) query the ID of a product where the name equals (=) a string
- w) the same, but now compare case-insensitively using
UPPER
Document the SQL commands you used and explain the actual query execution plan!
Exercise 11 (1p)¶
Analyze the following queries executed on the Product table:
- x) get the maximum of
Id - y) get the minimum of
Price
Document the SQL commands you used and explain the actual query execution plan!
Exercise 12 (1p)¶
Query the number of products per category (CategoryId).
Document the SQL commands you used and explain the actual query execution plan!
Exercise 13 (1p)¶
How could we improve on the performance of the previous query? Explain and implement the solution and repeat the previous query.
Tip
You need to add a new index. The question is: to which column?
Exercise 14 (1p)¶
List the Name of each Product where CategoryId equals 2.
Document the SQL commands you used and explain the actual query execution plan! Explain whether the index added in the previous exercises helps the performance.
Exercise 15 (1p)¶
Improve the performance of the previous query. Extend the index added before by including the name: right-click the index -> Properties -> and add Name to Included columns.
Repeat the previous query and analyze the plan.
Optional exercises¶
You can earn an additional +3 points with the completion of this exercise.
Exercise 16¶
Compare the following Invoice-InvoiceItem query: for each invoice item get the customer name.
SELECT CustomerName, Name
FROM Invoice JOIN InvoiceItem ON Invoice.ID = InvoiceItem.InvoiceID
Which join strategy was chosen? Explain why the system chose it!
Exercise 17¶
Compare the various JOIN strategies when querying all Product-Category record pairs.
Tip
Use query hints or the option command to explicitly specify the join strategy.
Put the 3 queries (each with a different join strategy) into one execution unit (execute them together). This will give you the relative cost of each option.
Document the SQL commands you used and explain the actual query execution plan!