Data-driven systems and the three- or multi-tier architecture¶
What is a data-driven system?¶
Every software handles data in some sense since the computer memory stores data, and the software manipulates this data. But not all applications are data-driven. A system or an application is called data-driven if its main purpose is to manage data.
In other words, the data-driven application is created to store, display, and manage data. The end-user uses this application to access the data within.
A chess game app also stores data in memory: the state of the chessboard. But the chess game app is not created to manipulate this data. The game is designed so that a user can play chess.
In a data-driven system, the data itself defines how the application operates. For example, based on a data record's specific attributes, deleting this record may be allowed or may be prohibited. Another example is how the Neptun system enables registration to an exam. The semester schedule, which defines the exam period, is data stored within the system itself. This schedule, stored as data, determines whether the end-user (here: the student) can register for an exam. The fact that the exam period starts on a different day each year does not mean that the software logic (i.e., software code) changes; the data makes the software behave differently.
Data-driven system example¶
The Neptun system is a typical example of a data-driven system. Its purpose is the management of all data related to courses, students, grades.
Another example is Gmail: it manages emails, attachments, contacts, etc. Every functionality of the application is about managing and displaying these data. And, of course, the data is stored securely, and every change in the system is persisted (i.e., not lost).
The structure of a data-driven system¶
Let us consider Gmail as an example. We would like to build a system which is capable of:
- sending and receiving emails,
- has a web application and a connected mobile app too,
- the UI supports multiple display languages,
- we can attach files,
- attachments can be referenced from Google Drive too,
- we can delay sending a composed email,
- etc.
Let us design
How do you start developing such a complex application?
This might be a complicated question. Let us begin with a more straightforward question. Supposing that the system already works, and now we want to add the delayed sending feature. How do we do this?
We could start a timer when the send button is clicked, and this timer, after a minute, sends the email. This will not work if the browser is closed before the countdown is over.
We could add the scheduled date of sending to the email as data. We can translate this as an architectural decision: delayed sending is not the responsibility of the user interface. We have not decided yet, which part of the application will be responsible, but we already know it must not be the UI.
Let us consider a similar question.
The received date of an email should be displayed to the user according to their preference, i.e., in Europe, 15:23 is the preferred date format, while other parts of the world might prefer 3:23 PM. Does this mean that the email as a data record has multiple received dates? Obviously not. The received date is a single date in a universal representation that is transformed by the UI to the appropriate format.
To summarize, we established that there are functionalities that the UI is responsible for, and there are other functionalities that the UI has nothing to do with. Now we arrive at the three- or multi-layer architecture.
The three- or multi-layered architecture¶
Data-driven systems are usually built on the three- or multi-layered architecture. The two names are treated as synonyms here. This architecture defines three main components:
- the presentation layer (or UI),
- the business layer,
- and the data access layer.
Besides these, the architecture also includes:
- a database or external data sources;
- and the so-called cross-cutting concerns (see later).
The application components are organized such that each component belongs to a single layer, and each layer has its responsibilities. This logical grouping of components enables the software developer to design components with clear responsibilities and well-defined boundaries.
Why multi-layered when it only has three?
The multi-layered terminology enables each of the previously listed layers to be further decomposed into sub-layers depending on complexity. In other words, an architecture is multi-layered if it has more than two layers. (In the two-layered architecture, the UI and the business logic are not separated.)
The layers not only have their responsibilities, but also define their interface provided to the layers on top of them. The data access layer specifies the operations the business layer can use to retrieve data; similarly, the business layer defines the functionalities the presentation layer can build upon. Each layer is allowed to communicate only with the layer directly beneath. For example, the presentation layer is not allowed to execute a SQL query in the database. At the same time, the implementation behind the well-defined communication interface can change, enabling easier maintenance of the software codebase.
By having the software split into layers, we can also move the layers to multiple servers (e.g., to handle larger loads). The simplest form is when the presentation layer runs in a browser on the user's machine, while the rest is hosted on a remote server. The database is also frequently offloaded to a dedicated server. Running the various layers on separate servers is usually motivated by performance reasons.
Layer / tier
The name of the architecture distinguishes the logical and physical separation of the components. Layers mean logical separation hosted on a single machine. Tiers indicate that at least some of the components have dedicated servers.
A system built on a well-designed architecture can be used and maintained over a long period. The separation of layers is neither a burden nor a set of mandatory rules. Instead, the layered architecture is a helpful guide for the software developer. When we develop a three-layered architecture, we must understand the layers, roles, and responsibilities.
The layered architecture does not mean that a functionality is present in a single layer. Most features offered to the end-user have some display in the presentation layer, handle data in the business logic layer, and store data in the database.
The codebase of a three-layered architecture also reflects the separation of the layers. Depending on the capabilities and the conventions on the given platform, the layers all have a dedicated project or package. This structure also enforces one-way dependencies, as the dependency-graph of projects/packages usually does not allow cycles. That is, if the business layer uses the data access layer, the latter one cannot use the former one.
The three-layered architecture is not the only possibility for implementing a data-driven application. Small and simple applications can be built using the two-layered architecture, while larger and more complex applications usually need further separation (e.g., using the microservices architecture).
The responsibilities of the layers¶
Let us examine the layers in more detail. The following diagram represents the architecture.
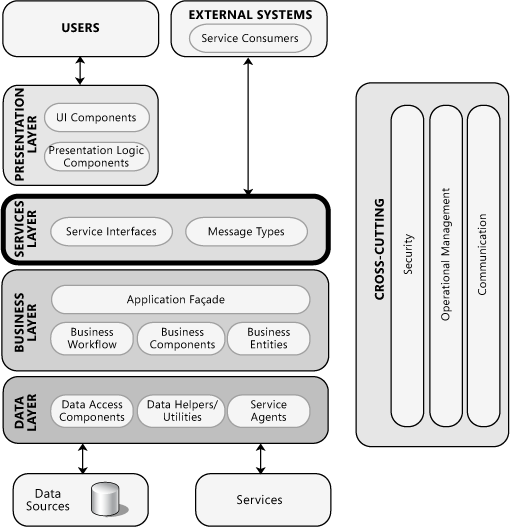
Source
Microsoft Application Architecture Guide, 2nd Edition, https://docs.microsoft.com/en-us/previous-versions/msp-n-p/ee658109%28v%3dpandp.10%29
We will discuss the layers from bottom-to-top.
Data sources¶
The most common data source is a database. It can be a relational-, or a NoSQL database. Its main purpose is the stable, reliable and persistent storage of data. These databases are usually software from a well-known third-party. This component is often hosted on a dedicated server accessible through a local network.
Sometimes our application might also work with data outside of our database, hosted by third-party services, that we use similarly to databases. For example, you can attach files in Gmail from Google Drive. Gmail, in this example, fetches the list of available files from Google Drive for the user to select the attachment. Google Drive is not a database, yet it is used as a data source.
These kinds of external services are grouped with our database, in the architectural sense, because they provide data storage and retrieval services, just like a traditional database. We have no information about their internal operations, and there is no need for users to understand it either. Thus, these services are treated similarly in our architecture.
Recently, more and more modern database management systems communicate over HTTP and often offer REST-like interfaces. These trends tend to blur the line between databases and external data sources.
Data access layer¶
The responsibility of the data access layer, DAL in short, is to provide convenient access to our data. The main functionality offered here is the storage, retrieval, and modification of data items, data records.
The data sources and the data access layer combined is often called the data layer.
The data access components provide a bridge towards the databases. Their role is to hide the inherent complexity of data management, and provide these as a convenient service to the upper layers. This includes working with SQL commands, as well as mapping the scheme of the database to a different scheme, consumed by the business layer.
When the data is not inside our database, the service agents provide similar services and handle the communication aspects with the external service.
This entire layer is often built on a particular technology used to communicate with the database, such as ADO.NET, Entity Framework, or JDBC, JPA, etc. The source code in this layer is often tightly coupled with these data access technologies. It is essential to keep these implementations inside this layer and not let it "leak" out.
IMPORTANT
In well-designed systems SQL commands appear only in the data access layer; under no circumstances do other layers assemble or execute SQL queries.
Since the data modeling scheme used in databases (i.e., the relational model) and the object-oriented modeling are based on different concepts, this layer is responsible for providing a mapping between the two worlds. The foreign keys used by the relational scheme are transformed into associations and compositions, and we may even need to perform data conversion between data types supported by the various systems. We will revisit these issues later.
Communication with an external system, whether it is a database or a third-party service requires specific techniques. For example, establishing network connections, performing handshakes, and managing the lifetime of these connections is important for performance reasons. Establishing certain kinds of connections, such as HTTP, are usually simple; but connecting to a database server using proprietary protocols may be more complex. Therefore, it is the responsibility of the data access layer to manage these connections and use appropriate techniques, such as connection pooling, when necessary. These details are often automatically controlled by the libraries we use.
The management of concurrent data accesses and related problems is also the responsibility of this layer. We will discuss this in detail later. We should keep in mind that multiple users usually use a three-layered application/system at the same time (just think of the Neptun system or a webshop), thus concurrent modifications can happen. We will discuss how this is handled and what type of issues we have to resolve.
Business Layer¶
The business layer is the "heart" of our application. The databases, the data access layer and the presentation layer are created so that the system can provide the services implemented in the business logic layer.
This layer is always specific to the problem domain. The Neptun system manages exams, semester schedules, grades, etc.; a webshop will, on the other hand, manage products, orders, searches, etc.
From a high-level point of view this layer is built of:
- business entities,
- business components,
- and business workflows.
The entities contain the data of our domain. Depending on the goal of the system, entities might cover products and product rating (e.g., in a webshop), or courses and exams (e.g., in Neptun).
The entities only store data; the components are responsible for manipulating these entities. The components implement the building blocks of the complex services offered by our system. Such a building block is, for example, finding a product in a webshop by name.
The workflows are built on these basic services. The workflows represent the functionalities that the end-users will carry out. A workflow may use multiple components. A classic example of a workflow is the checkout procedure in a webshop: check the products, finalize the order, produce an invoice, send a confirmation email, etc.
Service interfaces¶
The architecture diagram above has a services sub-layer. This is considered to be part of the business layer. Its purpose is to provide an interface through which the business logic layer's services can be accessed.
Generally, all layers have such interfaces published towards the layer built on top of them. The business layer is not unique in this sense. However, it is common nowadays that a business layer has not one, but multiple such interfaces published. The reason for multiple service interfaces is the presence of multiple presentation layers. Just take Gmail as an example: it has a web frontend and mobile apps too. The UIs are similar, but they do not provide identical behavior; therefore, the services consumed by the presentation layers also vary.
It is equally common that our application offers a UI and has public API (application programming interface) for allowing third-party integration. These APIs often offer different functionalities than the user interface and also frequently use other transport technologies; hence the need for a dedicated service interface.
By our application publishing an API, it can effectively act as a data source for third-party applications.
We will talk more about publishing services over various APIs. We will consider the web services and the REST technologies too.
Presentation layer¶
The terminologies presentation layer, UI, and user interface are commonly used interchanged. The responsibility of this layer is the presentation of the data to the end-user in a convenient fashion and the triggering of operations on these data.
Visualizing the data must consider how the data is "consumed." For example, when listing lots of records, the UI shall provide filtering and grouping too.
Sorting and filtering
Depending on the chosen technology stack, sorting and filtering may also involve other layers. When dealing with large data sets, it is usually not useful to send every record to the UI to perform filtering and sorting there. It would be an unnecessary network overhead, and some/most UI technologies are not exactly designed to handle large data sets. On the other hand, if the data set is not extensive, it is convenient to let the UI handle these aspects to provide faster and more fluent responses (not having to forward filtering to the database).
While displaying the data, the presentation layer is also responsible for performing simple data transformations, such as the user-friendly display of dates. As we discussed previously, a date might be printed as "15:23" or as "3:23 PM," or better yet, as "15 minutes ago."
Furthermore, the presentation layer also handles localization. Localization is about displaying all pieces of information according to a chosen culture, such as dates, currencies, numbers.
And finally, the UI handles user interactions. When a button is clicked, the UI translates this to an operation it will request from the business layer.
User input must be validated. Validation covers filling required fields, accepting only valid email addresses, handling expected number ranges, etc.
Validation
It is not enough to perform validation only in the user interface. Depending on the technology used, the UI can often be easily bypassed, and the services in the background can be called directly. If this happens and only the UI performs validation, invalid data can get into the system. Therefore, the validation is repeated by the business layer too. Regardless, the UI should still perform validation to give instant feedback to the user.
This layer is not discussed further in this course.
Cross-cutting services / Cross-cutting concerns¶
Cross-cutting services or cross-cutting concerns cover aspects of the application that are not specific to a single layer. When designing our system, we strive to have a unified solution to the problems raised here.
Security¶
Security-related services cover
- user authentication,
- authorization,
- tracing and auditing.
Authentication answers the question "who are you" while authorization determines "what you are allowed to do in this system."
Authentication covers not only the authentication on the user interface. We need to authenticate ourselves in the database too, not to mention accessing a third-party external system. Therefore this aspect is present in multiple layers.
We have various options. We can use custom authentication, directory-based authentication, or OAuth. After our system has authenticated a user, we can decide to use this identity in external services (e.g. Gmail fetches the user's files from Google Drive ) or use a central identity (e.g. sending an email notification in the name of a send-only central account).
Authorization is about access control: whether users can perform specific actions in the system. The UI usually performs some level of authorization (e.g., to hide unavailable functionality), but as discussed with input validation, the business layer must repeat this process. It is crucial, of course, that these two procedures use the same ruleset.
Tracing and auditing make sure that we can check who made specific changes in the system. Its main goal is to keep malicious users from erasing their tracks. Recording the steps and operations of a user may be formed in the business logic layer as well as in the database.
Operation¶
Keeping operational aspects in mind helps build maintainable software. The operational aspect usually covers error handling, logging, monitoring, and configuration management.
Centralized error management should catch all types of errors that are raised in an application. These errors need to be recorded (e.g., by logging them), and usually, the end-user needs to be notified (e.g., whether they should retry or wait for something else). Recording all exceptions is vital because errors raised in the lower layers of the application are not "seen" by anyone (but the end-user probably) unless these are adequately treated and recorded.
Logging and monitoring help both diagnostics and seeing whether a system behaves as intended. Logging is usually performed by writing a text log file. Monitoring, on the other hand, records so-called KPIs, key performance indicators. For example, KPIs are the memory usage, the number of errors, the number of pending requests, etc.
And finally, configuration management is about the control of the system configuration. Such configuration is, for example, server addresses (e.g., the database IP). Or we may also want to configure and change the background color of our UI centrally. The standard approach regarding configuration is to not hard-code them but instead offer re-configuration without re-compiling the application when the operational circumstances change. This might involve configuration files or more complicated configuration management tools.
We will not deal with these operational aspects in more detail. Often the chosen platform offers solutions to these problems.
Communication¶
By communication, we mean the method and format of data exchange between the layers and the components. Choosing the correct approach depends not only on the architecture but on the deployment model too. If the layers are moved to separate servers, network-based communication is needed, while communication between components on the same server can be achieved with simpler methods.
Today, most systems use network communication: most commonly to reach the database and other data sources, and frequently between the presentation layer and the service interfaces. Nowadays, most communication is HTTP-based, however when performance is a concern, TPC-based binary communication methods provide better alternatives. And in more complex systems where the layers themselves are distributed across servers too, messages queues are often used.
Encryption is also a factor in communication. Communication over public networks must be encrypted. In case of the communication between the UI and the service interface, this typically means HTTPS/TLS.
Backend and frontend¶
When we are talking about data-driven systems we often speak about backend and frontend. The frontend is mostly the user interface, that is, the presentation layer (a web application hosted in a browser, a native mobile app, a thick-client desktop app, etc). This is what the user interacts with. The backend is the service that provides the data to the UI: the APIs, the business layer, the data access layer, and the databases.
Depending on the chosen frontend technology, parts of the user interface might be created by the backend, though. This is called server-side rendering.
In this course, we will talk about backend technologies.
Questions to test your knowledge¶
- What are the layers in the three-layered architecture? What are their responsibilities?
- What are the cross-cutting services?
- Decide, whether the following statements are true or false:
- The presentation layer is responsible for validating data input.
- We shall try to avoid using SQL commands in the business layer.
- The layers in the three-layered architecture are always hosted on separate servers.
- The three-layered architecture becomes a multi-layered one when the business layer is moved to its own server.
- The layered architecture ensures that the implementation of the layers can change without this affecting the other layers.
- The frontend and the presentation layer are one and the same.
- Exception handling is important only in the business logic layer.