Transactions in databases¶
Context
When we talk about transactions, we mean relational databases. The problem and the solutions, however, are generic and are not specific to relational databases.
Concurrent data access¶
Database management systems are based on a client-server architecture. The client (the software we write) connects to the database and executes queries. We should always remember that there is a single database, but multiple clients are involved here. The purpose of the database system is to serve as many requests as possible; consequently, it executes the queries concurrently. In such a concurrent system, data access can overlap in the following ways.
- If the concurrent data access (either read or write) concerns independent data, there is no problem, and the operations may proceed concurrently.
- If all operations only read data, there is no issue either; multiple readers can access the same data.
- However, if the same data is accessed simultaneously and there is at least one writer, a concurrency problem may manifest itself.
This concurrency issue is analogous to the mutual exclusion problem known in operating systems and the various programming languages and frameworks. Concurrent data access in these scenarios usually involves mutual access to shared memory space, and the solution is to ensure mutual exclusion using some kind of guard.
In database management systems, concurrency is related to the records (rows) of database tables, and the guards are transactions.
Transactions¶
Definition
A transaction is a logical unit of a process, a series of operations that only make sense together.
A transaction combines operations into one unit, and the system guarantees the following properties:
- atomic execution,
- consistency,
- isolation from each other,
- and durability.
Let us examine these basic properties to understand how concurrent data access issues are resolved with their help.
A transaction is just a tool
A transaction, similarly to mutexes provided by an operating system or programming framework, is just a tool provided to the software developer. The proper usage is the responsibility of the developer.
Transactions basic properties¶
Atomicity¶
Atomic execution means that we have a sequence of operations, and this sequence is meaningful only when all of it is executed. In other words, partial execution must be prohibited. In database systems, we often need multiple statements to achieve our goal, hence the sequence of steps.
Let us imagine the checkout process in a webshop:
- The order is recorded in the database with the provided data
- The amount of stock is decreased by one since one piece was sold
These steps only make sense together. Given that an order has been recorded, the amount of stock must be compensated; otherwise, the data becomes invalid, and we sell more products than we have. Thus, we must not abort the sequence of steps in the middle.
This is what atomicity guarantees: if executing a sequence of steps has begun, all steps have to complete successfully or the initial state before the modification must be restored.
Consistency¶
The database's consistency rules are described by the integrity requirements, such as the record referenced by a foreign key must exist. There are other types of consistency requirements; e.g., there cannot be more students registered for an exam than the limit in the Neptun system.
Transactions ensure that our database is always in a consistent state. While a transaction is in progress, temporary inconsistencies may arise, similarly to the interim state between the two steps of the sequence of the operation above. However, at the end of the transaction, consistency must be restored. In other words, transactions enforce transition between consistent states.
Durability¶
Durability prescribes that the effect of a transaction is durable, that is, the results are not lost. Practically, it means that the modifications performed by a transaction must be flushed to persistent storage (i.e., disk).
There are two types of errors in database systems that can lead to data corruption: soft crash and hard crash. Soft crash means the database process terminates, and the content of memory is lost. Transactions offer protection from these kinds of crashes. A hard crash means that the disk is also affected. Only a backup can provide protection here.
Isolation¶
By isolation, we mean to isolate the effect of transactions from each other. That is, when writing our query, we do not need to concern ourselves with other concurrent transactions; the system will handle this aspect. The developer can write queries as if they were executed in the system alone, and the system will guarantee that it will prohibit those concurrency issues that we do not want to deal with.
The system will still run transactions concurrently. However, it guarantees to schedule the transactions to not violate the rules of the isolation level requested by the transaction. Therefore, all transactions need to specify the requested isolation level.
Isolation problems and isolation levels¶
Before we can discuss the isolation levels, we need to first understand the types of problems that concurrency can cause.
Problems¶
Dirty read¶
A dirty read means that a transaction accesses the uncommitted data of another transaction:
- A transaction modifies a record in the database but does not commit yet.
- Another transaction reads the same record (in its changed state).
- The first transaction is aborted, and the system restores the record to the state it was in before the change.
The transaction that read the record in the second step is now working with invalid, non-existent data. It should not have read it.

Source
Source of images: https://vladmihalcea.com/2014/01/05/a-beginners-guide-to-acid-and-database-transactions/
Should be avoided
Dirty read should almost always be avoided.
Lost update¶
During a lost update, two writes conflict:
- A transaction changes a record.
- Another transaction overwrites the same record.
The database has the result of the second write as if the first did not even happen.

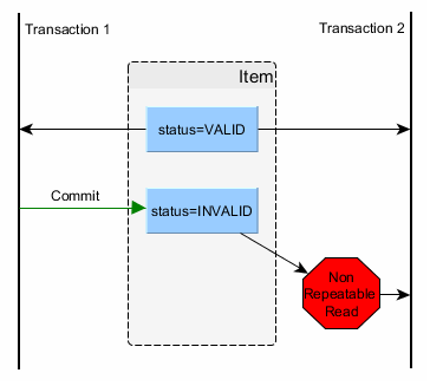
Non-repeatable read¶
A non-repeatable read means that the result of the query depends on the time it was issued:
- A transaction queries a record.
- A different transaction changes the same record.
- If the first transaction re-executes the same query as before, it gets a different result.
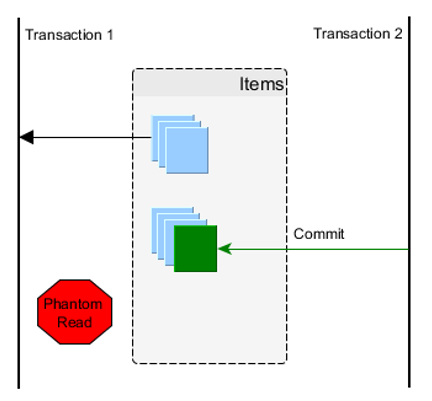
Phantom records / phantom read¶
We face the problem of phantom records when we work with recordsets:
- A transaction executes a query that yields multiple records as a result.
- Meanwhile, a different transaction deletes a record that is included in the previous result set.
- The first transaction starts processing its result set (e.g., iterates over the records one by one).
Should the deleted record be processed now? We can imagine a similar scenario when a record is altered in the second step. Which state should the reader transaction in step three see? The one before, or the one after the modification?
Isolation levels¶
The problems discussed before can be avoided by using the right isolation level. We should consider, though, that the "higher" the level of isolation we prescribe, the lower the throughput of the database system will be. Also, we might face deadlocks (see below). Our goal, thus, is a compromise between a suitable isolation level and performance.
The ANSI/ISO SQL standard defines the following isolation levels:
- Read uncommitted: offers no protection.
- Read committed: no dirty read.
- Repeatable read: no dirty read and no non-repeatable read.
- Serializable: prohibits all issues.
What to use?
Read uncommitted is seldom used. Serializable, similarly, is avoided if possible. The default, usually, is read committed.
Scheduling enforced with locks¶
The database enforces isolation through locks: when a record is accessed (read or write), it is locked by the system. The lock is placed on the record when it is first accessed and is removed at the end of the transaction. The type of lock (e.g., shared lock or mutually exclusive) depends on the isolation level and the implementation of the database management system.
These locks, in effect, enforce the scheduling of the transactions. When a lock is not available because the record is used by another transaction and concurrent access is not allowed by the isolation level, the transaction will wait.
We know that when we use locks, deadlock can occur. This is no different in databases. A deadlock may occur when two transactions are competing for the same locks. See the figure below; a continuous line represents an owned lock, while the dashed ones represent a lock the transaction would like to acquire. Neither of these requests can be fulfilled, resulting in both transactions being unable to move forward.
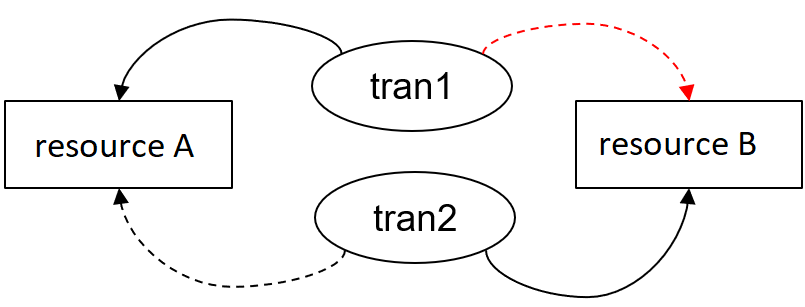
Deadlocks cannot be prevented in database management systems, but they can be recognized and dealt with. The system monitors locks, and when a deadlock is detected one of the transactions is aborted and all its modifications are rolled back. All applications using a database must be prepared to handle this.
Retry is the only resolution
When a deadlock happens, there is usually no other resolution than retrying the operation later (e.g., automatically, or manually requested by the end-user).
Transaction boundaries¶
A transaction combines a sequence of steps. It is, therefore, necessary to mark the beginning and the end of the transaction. The way transaction boundaries are signaled may depend on the platform, but generally:
-
All operations are executed within the scope of a transaction. If the transaction boundary is not marked explicitly, each statement is a transaction in itself.
Simple statements are transactions too
Since all SQL statements run within a transaction scope, the transaction properties are automatically guaranteed for all statements. For example, a
deletestatement affecting multiple records cannot abort and delete only half of the records. -
The developer executes a
begin transactionSQL statement to start a transaction, and completes it either withcommitorrollback. Commit completes the transaction and saves its changes, while rollback aborts the transaction and undoes its changes.Nested transactions
Some database management systems enable nested transactions too. Completing transactions follow the nesting: each level needs to be committed.
Transaction logging¶
So far, we have covered what transactions are used for. Let us understand how they work internally.
Transactional logging is the process used by the database management system to track the pending modifications of running transactions, allowing these changes to be rolled back in case of abort or soft crash.
To understand transactional logging, let us consider the following system model.
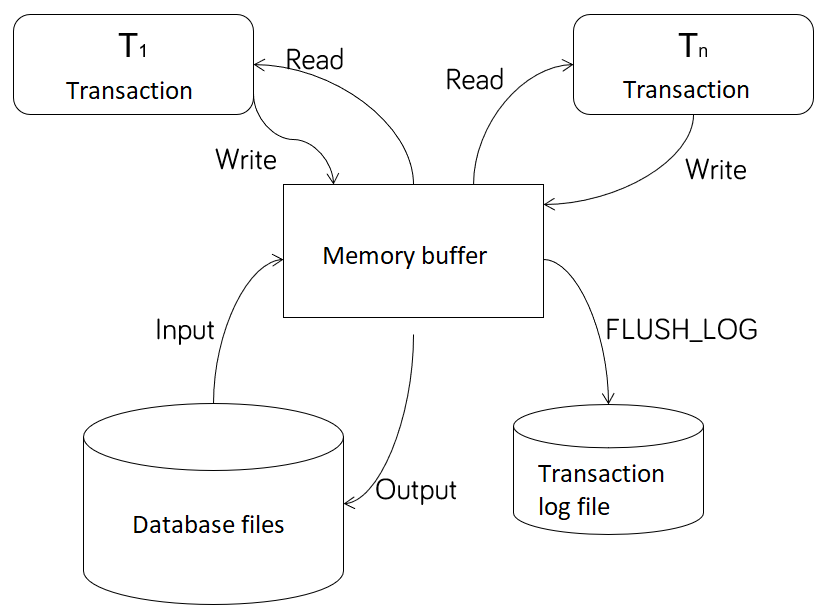
This conceptual model includes the following operations:
- Begin T(x): Start of transaction
- Input(A): Read data from the durable database store (disk)
- Output(A): Write data to durable database store (disk)
- Read(A): Transaction reads the data from the memory buffer
- Write(A): Transaction writes the data to the memory buffer
- FLUSH_LOG: Write the transaction log to disk
The process of transactional logging is demonstrated in the following example. In this example, a transaction modifies two data elements: A is decreased by 2, and B is increased by 2.
Undo transaction log¶
We begin with an empty memory buffer. All data is on disk. The process starts by reading the data from disk.
| Operation | A (database) | B (database) | A (buffer) | B (buffer) | Transactional log |
|---|---|---|---|---|---|
| Begin(T1) | 10 | 20 | - | - | Begin T1 |
| Input(A) | 10 | 20 | 10 | - | |
| Input(B) | 10 | 20 | 10 | 20 |
The transaction has all the necessary data in the memory buffer. The modification is performed, and the data is written back to the buffer. At the same time, the original values are written to the transaction log.
| Operation | A (database) | B (database) | A (buffer) | B (buffer) | Transactional log |
|---|---|---|---|---|---|
| Read(A) | 10 | 20 | 10 | 20 | |
| Write(A) | 10 | 20 | 8 | 20 | T1, A, 10 |
| Read(B) | 10 | 20 | 8 | 20 | |
| Write(B) | 10 | 20 | 8 | 22 | T1, B, 20 |
The transaction completes, and it saves the changes. The transaction commits, which first flushes the transaction log to disk, then the changes are persisted to disk.
| Operation | A (database) | B (database) | A (buffer) | B (buffer) | Transactional log |
|---|---|---|---|---|---|
| Flush_LOG | 10 | 20 | 8 | 22 | |
| Output(A) | 8 | 20 | 8 | 22 | |
| Output(B) | 8 | 22 | 8 | 22 | |
| Commit T1 |
How can the consistent state be restored in case of a soft crash?
- Suppose the transaction is aborted before the commit. There is no action needed, as the database files on disk contain the original values, and the memory buffer is lost during the crash.
- If the transaction is in the middle of the commit procedure, some data could already be written to disk. These need to be reverted. The transaction log is processed starting from the end, and for all transactions that have no commit mark in the log, the values must be restored to their original state.
To summarize, when using undo logging:
- the database cannot be modified until the transaction log is flushed,
- and the commit mark must be placed into the log once the database writes are finished.
The key is to flush the transaction log before the changes are persisted. The drawback of this method is that the transaction log is flushed twice, which is a performance issue due to the cost of disk access.
Redo transaction log¶
The process starts with reading the data from disk, followed by performing the modifications, but this time the final values are written to the transaction log.
| Operation | A (database) | B (database) | A (buffer) | B (buffer) | Transactional log |
|---|---|---|---|---|---|
| Read(A) | 10 | 20 | 10 | 20 | |
| Write(A) | 10 | 20 | 8 | 20 | T1, A, 8 |
| Read(B) | 10 | 20 | 8 | 20 | |
| Write(B) | 10 | 20 | 8 | 22 | T1, B, 22 |
To finalize the transaction, the log is flushed first to register the modified values - but no modification is made to the database files yet. Thus, the transaction log needs to be written to disk only once (compared to the undo logging scheme).
| Operation | A (database) | B (database) | A (buffer) | B (buffer) | Transactional log |
|---|---|---|---|---|---|
| Commit T1 | |||||
| Flush_LOG | 10 | 20 | 8 | 22 |
After the transaction log is persisted, the changes are committed to the database files.
| Operation | A (database) | B (database) | A (buffer) | B (buffer) | Transactional log |
|---|---|---|---|---|---|
| Output(A) | 8 | 20 | 8 | 22 | |
| Output(B) | 8 | 22 | 8 | 22 |
How can the consistent state be restored in case of a soft crash?
- Suppose the transaction is aborted before the commit. In that case, there is no action needed, as the database files on disk contain the original values, and the memory buffer is lost during the crash.
- If the transaction is in the middle of the commit procedure, the commit mark is flushed to the log, but no changes were made to the database yet. Restoring from an aborted state at this stage is performed by processing the transaction log from the beginning and redoing all committed transactions.
To summarize, when using redo logging:
- the database cannot be modified until the transaction log is flushed,
- commit mark must be placed into the transaction log before writing the database files.
There are fewer transaction log flushes in this scheme compared to undo logging; however, the restore procedure is longer.
Undo/redo logging¶
As the name suggests, this is the combination of the two schemes. The process starts just like in the previous cases. The difference is in writing the transaction log: both the original and the modified values are written to the log.
| Operation | A (database) | B (database) | A (buffer) | B (buffer) | Transactional log |
|---|---|---|---|---|---|
| Read(A) | 10 | 20 | 10 | 20 | |
| Write(A) | 10 | 20 | 8 | 20 | T1, A, 10, 8 |
| Read(B) | 10 | 20 | 8 | 20 | |
| Write(B) | 10 | 20 | 8 | 22 | T1, B, 20, 22 |
The commit procedure is simpler. The order of writing the database files and writing the commit mark into the transaction log is no longer fixed - however, flushing the transaction log must still be performed first. The simplification, therefore, is that the place of the commit mark is not fixed.
| Operation | A (database) | B (database) | A (buffer) | B (buffer) | Transactional log |
|---|---|---|---|---|---|
| Flush_LOG | 10 | 20 | 8 | 22 | |
| Output(A) | 8 | 20 | 8 | 22 | |
| Commit T1 | |||||
| Output(B) | 8 | 22 | 8 | 22 |
Restore needs to combine the procedures discussed before:
- committed transactions are replayed (just like in redo logging),
- while aborted transactions are reverted (just like in undo logging).
This solution has the following advantages:
- there is less synchronization during the commit procedure (with regards to writing the transaction log and the database files),
- the changes can be persisted in the database files sooner (no need to wait for writing the commit mark).
Reducing the transaction log¶
The transaction log needs to be emptied periodically. Transactions that are committed and persisted into the database files can be purged from the log. Similarly, aborted transactions that were reverted can also be removed. This is performed automatically by the system, but can also be triggered manually.
Long-running transactions and the transaction log
Long-running transactions can significantly increase the size of the log. The larger the log is, the longer the purging process will take.
Extracting deadlock information from MSSQL database¶
Deadlock
A deadlock in a system can occur if there are locks. A deadlock can occur if at least two transactions want to obtain the same locks simultaneously.
Let there be transactions A and B and resources a and b. Transaction A already locks resource a, while transaction B locks resource b. Then, let us assume that transaction A wants to lock resource b and transaction B also wants to lock resource a. In this case, a deadlock will occur.
Let us take the previous example and see how we can diagnose the deadlock once it occurs in MSSQL. To do this, first, we need to cause the deadlock artificially.
-
Let us create two tables on which to generate the deadlock artificially.
Create the first table called
Lefty, which will have an attribute calledNumbers:CREATE TABLE dbo.Lefty (Numbers INT PRIMARY KEY CLUSTERED); INSERT INTO dbo.Lefty VALUES (1), (2), (3);Create a second table called
Righty, which will also have an attribute,Numbers:CREATE TABLE dbo.Righty (Numbers INT PRIMARY KEY CLUSTERED); INSERT INTO dbo.Righty VALUES (1), (2), (3); -
The two transactions must run simultaneously for a deadlock to occur. If we test manually, this is difficult to achieve, so the order of execution is:
- Execute the first
UPDATEstatement from the first transaction - From the second transaction, execute both
UPDATEstatements - Execute the second
UPDATEstatement from the first transaction
First transaction:
BEGIN TRAN UPDATE dbo.Lefty SET Numbers = Numbers * 2; GO UPDATE dbo.Righty SET Numbers = Numbers * 2; GOSecond transaction:
BEGIN TRAN UPDATE dbo.Righty SET Numbers = Numbers + 1; GO UPDATE dbo.Lefty SET Numbers = Numbers + 1; GO - Execute the first
Now we have a deadlock. The system will automatically resolve this soon. Before that happens, we can check what we see in the system.
The locks placed by the transactions can be queried in the database with the following query:
SELECT
OBJECT_NAME(P.object_id) AS TableName,
Resource_type, request_status, request_session_id
FROM
sys.dm_tran_locks dtl
JOIN sys.partitions P
ON dtl.resource_associated_entity_id = p.hobt_id
In our example, the result of this query is:
| TableName | Resource_type | request_status | request_session_id | |
|---|---|---|---|---|
| 1 | Righty | KEY | GRANT | 54 |
| 2 | Lefty | KEY | GRANT | 53 |
So the first transaction placed a lock on the Lefty table, while the second transaction placed it on table Righty.
The database also provides information data about blocked transactions that we can query with the following SQL statement:
SELECT blocking_session_id AS BlockingSessionID,
session_id AS VictimSessionID,
wait_time/1000 AS WaitDurationSecond
FROM sys.dm_exec_requests
CROSS APPLY sys.dm_exec_sql_text([sql_handle])
WHERE blocking_session_id > 0
In our example, the result of this query is:
| BlockingSessionID | VictimSessionID | WaitDurationSecond | |
|---|---|---|---|
| 1 | 54 | 53 | 0 |
| 2 | 53 | 54 | 72 |
This means that the transaction with ID 53 waits for the transaction with ID 54, and the transaction with ID 54 waits for the transaction with ID 53.
The deadlock is soon eliminated automatically by the database. If we want to intervene manually, we can do so with the kill command, selecting the transaction to stop (e.g., kill 53).
Distributed transactions¶
Up to this point, we assumed a single database in which ACID transactions can be enforced locally. In practice, however, a single logical transaction can span multiple databases or services.
CAP theorem and consistency¶
When data is globally distributed and replicated, communication failures are inevitable. The CAP theorem highlights a core trade-off. Any distributed data store can provide only two of the following three guarantees:
- Consistency: every read receives the most recent write (or an error).
- Availability: every request receives a non-error response, without guaranteeing it contains the most recent write.
- Partition tolerance: the system continues to operate despite messages being dropped or delayed between nodes.
Because failures are unavoidable at scale, systems often choose between:
- Strong consistency: replicas synchronize before answering. During partitions the system may delay/stop some operations to avoid divergence.
- Eventual consistency: the system prioritizes availability and allows replicas to diverge temporarily. They converge within a time window (the “inconsistency window”), depending on load and propagation delays.
Saga pattern¶
For business workflows which are long running (often involving user input or external systems), the traditional mode of committing/rolling back becomes impractical. A common alternative is the Saga pattern.
A saga splits the workflow into a sequence of local transactions, each with a compensating action. If a later step fails, the system runs compensations to semantically undo earlier steps. This trades immediate global atomicity for practicality as the system may be temporarily inconsistent while the saga is in progress, but it can still reach a correct final outcome.
Questions to test your knowledge¶
- What types of concurrent data access problems do you know?
- List the isolation levels. Which problems does each of the levels prohibit?
- What are the basic properties of transactions?
- Decide whether the following statements are true or false:
- The serializable isolation level seemingly, logically executes the transactions one after the other.
- Deadlock can be prevented by using the right isolation level.
- The default isolation level is usually read committed.
- If we are not using explicit transactions, then we are by default protected from the issue of dirty read.
- The transaction log offers protection against all kinds of data losses.
- In the redo transaction logging scheme, the transaction log starts with the commit mark.